08-1 해시의 개념
어떠한 값이 저장되는 위치를 어떤 규칙으로 정할 수 있다면 굳이 탐색을 할 필요 없이 바로 데이터를 찾아낼 수 있을 겁니다. 이런 생각을 바탕으로 만든 자료구자 해시(hash)입니다.
해시는 해시 함수를 사용해서 변환한 값을 인덱스로 삼아 키와 값을 저장해서 빠른 데이터 탐색을 제공하는 자료구조이다.
보통은 인덱스를 활용해서 탐색을 빠르게 만들지만 해시는 키(key)를 활용해 데이터 탐색을 빠르게 한다.
해시 자세히 알아보기
사실 생활에서도 해시를 많이 활용한다. 가장 쉽게 볼 수 있는 해시의 예는 연락처이다.
전화번호는 값(value), 값을 검색하기 위해 활용하는 정보는 키(key)이다.
그리고 그 사이에 키를 이용해 해시값 또는 인덱스로 변환하는 해시 함수가 있다.
해시의 특징
키 자체가 해시 함수에 의해 값이 있는 인덱스가 되므로 값을 찾기 위한 탐색 과정이 필요 없다.
- 해시는 단방향으로 동작한다. - 키를 통해 값을 찾을 수 있으나 값을 통해 키를 찾을 수 없다.
- 찾고자 하는 값을 O(1)에서 바로 찾을 수 있다.
해시를 사용하지 않는다면 어떻게 될까?
어떤 데이터를 찾으려면 전체 데이터를 확인해보는 방법밖에 없다.
즉, 순차 탐색을 통해 이름에 맞는 전화번호를 찾아야 한다.
반면, 해시를 사용하면 순차 탐색할 필요 없이 해시 함수를 활용해서 특정 값이 있는 위치를 바로 찾을 수 있어 탐색 효율이 좋다.
해시 테이블(hash table) : 키와 대응한 값이 저장되어 있는 공간
버킷(bucket) : 해시 테이블의 각 데이터
해시의 특성을 활용하는 분야
해시는 단방향인 대신 빠르게 원하는 값을 검색할 수 있다. 이런 특성으로 인해 데이터를 저장하고 검색하거나, 보안이 필요한 때에 활용된다.
- 비밀번호 관리 : 사용자의 비밀번호를 해싱한 비밀번호로 저장한다. 비밀번호가 맞는지 확인할 때도 마찬가지
- 데이터베이스 인덱싱 : 데이터베이스에 저장된 데이터를 효율적으로 검색할 때 해시를 활용한다.
- 블록체인 : 각 블록은 이전 블록의 해시값을 포함하고 이를 통해 데이터 무결성을 확인한다.
08-2 해시 함수
C++에서는 맵이라는 자료형(여기서 말하는 건 엄밀히 말하면 unordered_map을 말한다.)을 제공하는데 이 자료형은 해시와 거의 동일하게 동작하므로 해시를 쉽게 사용할 수 있다.
해시 함수를 구현할 때 고려할 내용
- 해시 함수가 변환한 값은 인덱스로 활용해야 하므로 해시 테이블의 크기를 넘으면 안된다.
- 해시 함수가 변환한 값의 충돌은 최대한 적게 발생해야 한다.(충돌의 의미는 서로 다른 두 키에 대해 해싱 함수를 적용한 결과가 동일한 것을 의미한다.)
자주 사용하는 해시 함수 알아보기
나눗셈법
나눗셈범(division method)은 키를 소수로 나눈 나머지를 활용한다. 이처럼 나머지를 취하는 연산을 모듈러 연산이라고 하며, 연산자는 %로 표시한다.
나눗셈법은 다음과 같이 수식으로 정리할 수 있다.
h(x) = x mod k
x는 키, k는 소수이다. 키를 소수로 나눈 나머지를 인덱스로 사용한다.
나눗셈범에 소수가 아닌 15를 사용하면 어떻게 될까?
소수를 사용하는 이유는 다른 수를 사용할 때보다 충돌이 적기 때문이다. 예를 들어 소수가 아닌 15를 나눗셈법에 적용했다고 할 때, x가 3의 배수인 경우 3, 6, 9, 12, 15부터 패턴처럼 다음 배수가 다시 3, 6, 9, 12, 15에 매핑되는 것을 알 수 있다.
즉, 이러한 충돌이 발생하므로 소수를 사용해서 나눗셈법을 적용한다.
왜 충돌이 많이 발생할까?
N의 약수 중 하나를 M이라고 한다면 임의의 수 K에 대해 M * K = N이 되는 수가 반드시 존재하기 때문이다. 그래서 소수를 적용하는 것이 좋다.
나눗셈법의 해시 테이블 크기는 K
K에 대해 모듈러 연산을 했을 때 나올 수 있는 값은 0 ~ (K - 1)이기 때문이다. 단, 아직까지 매우 큰 소수를 구하는 효율적인 방법은 없으며 필요한 경우 기계적인 방법으로 구해야 한다. 이것이 나눗셈법의 단점 중 하나이다.
곱셈법
곱셈법(multiplication method)는 나눗셈법과 비슷하게 모듈러 연산을 활용하지만 소수는 활용하지 않는다. 공식은 다음과 같다.
h(x) = (((x * A) mod 1) * m)
m은 최대 버킷의 개수, A는 황금비(golden ratio number)이다. 황금비*는 무한소수로 대략 1.6180339887...이다.
*황금비는 수학적으로 임의의 길이를 두 부분으로 나눌 때, 전체와 긴 부분의 비율이 긴 부분과 짤은 부분의 비율과 같은 비율을 말한다.
- 키에 황금비를 곱한다.
- 1.에서 구한 값에 모듈러 1을 취한다.(소수만 취한다) 소수 부분만 취하기 때문에 0.xxx 형태의 값이 나온다.
- 2.에서 구한 값을 가지고 실제 해시 테이블에 매핑한다. 테이블의 크기가 m이면 2.에서 구한 수에 m을 곱한 후 정수 부분을 취하는 연산을 하여 해시 테이블에 매핑 가능하다. .2에서 구한값은 0.xxx의 값이므로 매핑할 테이블의 크기인 m을 곱하면 테이블의 인덱스 범위인 0 ~ (m - 1)에 매치할 수 있다.
곱셈법의 장점은 황금비를 사용하므로 나눗셈법처럼 소수가 필요하지는 않다는 장점이 있다. 따라서 해시 테이블의 크기가 커져도 추가 작업이 필요 없다.
문자열 해싱
지금까지 알아본 해시 함수는 키의 타입이 숫자였지만, 타입이 문자열일 때도 사용할 수 있는 해시 함수인 문자열 해싱에 대해서 알아본다.
문자열 해싱은 문자열의 문자를 숫자로 변환하고 이 숫자들을 다항식의 값으로 변환해서 해싱한다.
이 때 사용되는 공식(혹은 함수)는 polynomial rolling method이다.
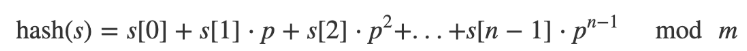
p*는 31이고, m은 해시 테이블 최대 크기이다.
*.p를 31로 정한 이유는 홀수이면서 메르센 소수이기 때문이다.
*.메르센 소수는 일반적으로 2^N - 1형식으로 표시할 수 있는 숫자 중 소수인 수를 말한다. 메르센 소수는 해시에서 충돌을 줄이는데 효과적이라는 연구 결과가 있다고 책의 저자가 언급한다. 찾아보니 메르센 소수가 균등 분포의 이점과 모듈러 연산 시 빠른 비트 단위 연산이 가능해 일반 소수가 아닌 메르센 소수를 사용한다고 한다.
- 알파벳 a부터 z까지 숫자와 매치한 표와 키s(문자열 apple이 a, p, p, l, e로 s 배열에 들어가 있다)가 존재할 때,
- 문자 'a'는 매치 표(알파벳 a가 1과 매칭, z가 26과 매칭된다)상 1이다. 따라서 "apple"의 'a'는 1이다.
- 그러므로 s[0] * p^0는 1*1이 되기 때문에 1이다.
- 두 번째 문자열 'p'에 대한 연산 => 'p'는 16이다. p^1을 곱하면 496이다.
- 이렇게 곱한 값들을 전부 더해주면 최종값은 4,990,970이다. 이를 해시 테이블의 크기 m으로 모듈러 연산하면 끝이다.(4990970%m)
기존에는 키 자체가 숫자였기에 바로 해시 함수를 적용했으나, 키가 문자열이면 각 문자열의 문자들을 적절한 숫자로 변경한 다음 해시 함수를 적용해야 한다. 이런 변환 과정을 통해 문자열이 키인 데이터에도 해시를 사용할 수 있다.
하지만, 해시 함수를 적용한 값이 해시 테이블 크기에 비해 너무 클 수 있다. 그래서 해시 함수가 내는 결과의 크기를 해시 테이블 크기에 맞도록 하는 작업이 필요하다.
"apple"이라는 문자열도 결괏값은 4,990,970으로 굉장히 큰 값이 나왔다. 다음과 같은 연산 법칙을 활용해 문자열 해시 함수를 수정할 수 있다.
문자열 해시 함수 수정하기
덧셈을 전부한 다음 모듈러 연산을 하는 왼쪽의 수식 대신, 오른쪽 수식처럼 중간 중간 모듈러 연산을 해 더한 값을 모듈러 연산하면 오버플로를 최대한 방지할 수 있다.
(a + b) % c = (a % c + b % c) % c
이를 활용해서 앞서 본 문자열 해싱 공식을 수정하면 된다.
!!. 해시 함수뿐 아니라 보통 수식에 모듈러 연산이 있는 문제 중 큰 수를 다루는 문제는 이런 오버플로 함정이 있는 경우가 많다. 난이도가 높은 문제는 대부분 이런 함정을 포함하고 있으니 기억해두면 좋다.
08-3 충돌 처리
서로 다른 키에 대해서 해시 함수의 결괏값이 같으면 충돌(collision)이라고 한다.
체이닝으로 처리하기
체이닝은 충돌이 발생하면 해당 버킷에 링크드리스트로 같은 해시값을 가지는 데이터를 연결한다.
충돌이 발생한 경우 체이닝 방식의 경우, 링크드리스트로 충돌한 데이터를 연결하며, 이후 어떤 데이터가 해시 테이블 상 같은 위치에 저장되어야 하는 경우 이런 방식으로 데이터를 저장한다. 간단한 해결 방법이지만 2가지 단점이 있다.
해시 테이블 공간 활용성이 떨어진다 : 충돌이 많아지면 그만큼 링크드리스트의 길이가 길어지고, 다른 해시 테이블의 공간은 덜 사용하므로 공간 활용성이 떨어진다.
검색 성능이 떨어진다 : 링크드리스트 자체의 한계로 인해 검색 성능이 떨어진다.(링크드리스트 제일 처음부터 검색하기 때문) 만약 N개의 키가 있으며 모든 키가 충돌하여 체이닝된 경우 마지막 버킷의 시간 복잡도는 O(N)이다.
개방 주소법으로 처리하기
개방 주소법(open addressing)은 체이닝에서 링크드리스트로 충돌값을 연결한 것과 다르게 빈 버킷을 찾아 충돌값을 삽입한다. 이 방법은 해시 테이블을 최대한 활용하므로 체이닝보다 메모리를 더 효율적으로 사용한다.
선형 탐사 방식
선형 탐사(linear probing) 방식은 충돌이 발생하면 다른 빈 버킷을 찾을 때까지 일정한 간격*으로 이동한다. 수식은 다음과 같다.
*. 보통 간격은 1로 하는 것이 일반적이다.
h(k, i) = (h(k) + i) mod m
m은 수용할 수 있는 최대 버킷이다. 선형 탐사 시 테이블의 범위를 넘으면 안 되므로 모듈러 연산을 적용한 것이다.
키가 5라고 할 때, 해시 함수를 적용하면 값 2가 있는 위치 정보를 참조하여 충돌이 발생한다고 가정한다.
이 때, 선형 탐사 방법으로 1칸씩 아래로 내려간다. 값이 계속 있어서 충돌한다면 충돌하지 않는 위치에 도달했을 때, 그 위치에 키 5를 넣는다. 하지만 이 방법에도 단점은 존재한다. 충돌 발생 시 1칸씩 이동하며 해시 테이블 빈 곳에 값을 넣으면 해시 충돌이 발생한 값끼리 모이는 영역이 생긴다. 이를 클러스터(cluster)를 형성한다고 한다. 이런 군집이 생기면 해시값이 겹칠(충돌할) 확률이 올라간다.*
*. 그래서 이를 방지하기 위해 제곱수만큼 이동하며 탐사하는 방법도 있다.
이중 해싱 방식
이중 해싱 방식은 말 그대로 2개의 해시 함수를 사용한다. 때에 따라 해시 함수를 N개로 늘리기도 한다.
두 번째 해시 함수의 역할은 첫 번째 해시 함수로 충돌이 발생하면 해당 위치를 기준으로 어떻게 위치를 정할지 결정하는 역할을 한다.
아래의 수식 중 h1은 1차 해시 함수, h2는 2차 해시 함수이다.
h(k, i) = (h1(k) + i*h2(k)) mod m
수식을 보면 선형 탐사와 비슷하게 더하는 방식으로 데이터의 위치를 정하지만 클러스터를 줄이기 위해 m을 제곱수로 하거나 소수로 한다.
실제 해시를 구현하라는 질문이 나오지 않더라도 실제 코딩 테스트 문제에서 해시 문제의 핵심은 키와 값을 매핑하는 과정임을 명심해야 한다.
특정 값이나 정보를 기준으로 빈번한 검색을 해야 하거나 특정 정보와 매핑하는 값의 관계를 확인해야 하는 작업이 문제에 있다면 해시를 고려해야 한다.
'책 정리 > 코딩 테스트 합격자 되기 C++ 편' 카테고리의 다른 글
| [코딩 테스트 합격자 되기 C++ 편] 07 큐 (0) | 2024.12.27 |
|---|---|
| [코딩 테스트 합격자 되기 C++ 편] 06 스택 (1) | 2024.12.27 |
| [코딩 테스트 합격자 되기 C++ 편] 05 배열 (1) | 2024.12.27 |
| [코딩 테스트 합격자 되기 C++ 편] 04 코딩 테스트 필수 문법 (0) | 2024.12.27 |
| [코딩 테스트 합격자 되기 C++ 편] 03 알고리즘의 효율 분석 (1) | 2024.12.27 |